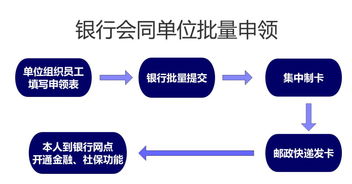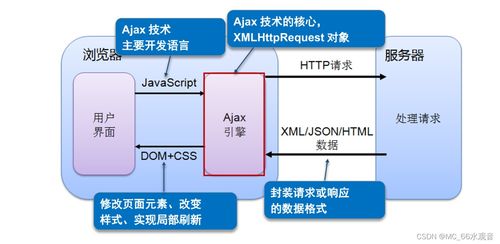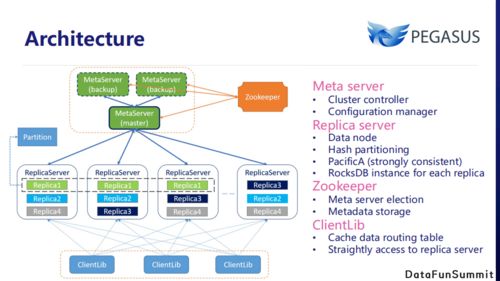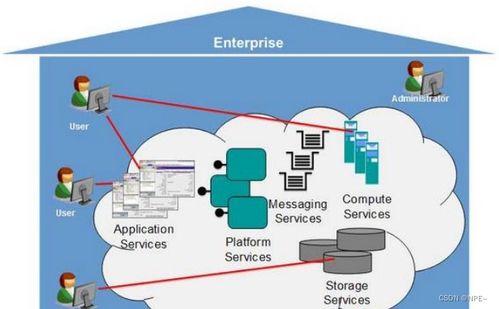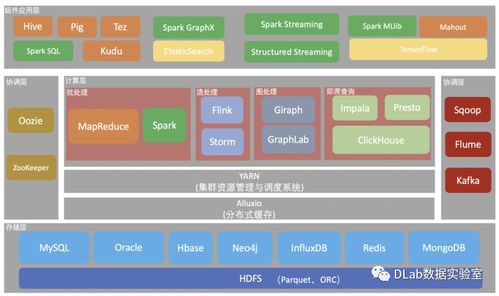
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,大數(shù)據(jù)計(jì)算生態(tài)構(gòu)成了企業(yè)數(shù)字化轉(zhuǎn)型和智能決策的核心引擎。這個(gè)龐大而精密的體系并非孤立存在,其高效運(yùn)轉(zhuǎn)仰賴(lài)于三個(gè)緊密協(xié)作、互為支撐的支柱:數(shù)據(jù)存儲(chǔ)、數(shù)據(jù)處理以及數(shù)據(jù)處理和存儲(chǔ)支持服務(wù)。它們共同構(gòu)成了從數(shù)據(jù)原始狀態(tài)到價(jià)值洞察的完整閉環(huán)。
一、 數(shù)據(jù)存儲(chǔ):海量信息的穩(wěn)固根基
數(shù)據(jù)存儲(chǔ)是大數(shù)據(jù)生態(tài)的“記憶體”,其核心任務(wù)是解決海量、多源、異構(gòu)數(shù)據(jù)的持久化保存與高效訪問(wèn)問(wèn)題。它已從傳統(tǒng)的集中式架構(gòu),演進(jìn)為適應(yīng)大數(shù)據(jù)特性的分布式、高可擴(kuò)展形態(tài)。
- 分布式文件系統(tǒng):以Hadoop HDFS為代表,它將超大規(guī)模數(shù)據(jù)集(PB級(jí)以上)分割成塊,分散存儲(chǔ)于廉價(jià)的商用服務(wù)器集群中,通過(guò)冗余機(jī)制確保高容錯(cuò)性,為批處理提供了高吞吐量的數(shù)據(jù)訪問(wèn)基礎(chǔ)。
- NoSQL數(shù)據(jù)庫(kù):針對(duì)關(guān)系型數(shù)據(jù)庫(kù)在處理非結(jié)構(gòu)化、半結(jié)構(gòu)化數(shù)據(jù)及高并發(fā)寫(xiě)入時(shí)的瓶頸應(yīng)運(yùn)而生。例如:
- 鍵值存儲(chǔ)(如Redis, DynamoDB):適用于高速緩存和會(huì)話存儲(chǔ)。
- 列式存儲(chǔ)(如HBase, Cassandra):擅長(zhǎng)快速查詢(xún)海量數(shù)據(jù)集中的特定列,適合實(shí)時(shí)讀寫(xiě)。
- 文檔數(shù)據(jù)庫(kù)(如MongoDB):以靈活的JSON/BSON格式存儲(chǔ),適配快速演變的業(yè)務(wù)模型。
- 圖數(shù)據(jù)庫(kù)(如Neo4j):專(zhuān)注于實(shí)體間復(fù)雜關(guān)系的存儲(chǔ)與遍歷。
- 數(shù)據(jù)湖與數(shù)據(jù)倉(cāng)庫(kù):
- 數(shù)據(jù)湖(通常基于HDFS、對(duì)象存儲(chǔ)如AWS S3)存儲(chǔ)原始、未經(jīng)加工的全量數(shù)據(jù),格式不限,支持探索式分析。
- 數(shù)據(jù)倉(cāng)庫(kù)(如Teradata、Snowflake、ClickHouse)則存儲(chǔ)經(jīng)過(guò)清洗、整合、建模的結(jié)構(gòu)化數(shù)據(jù),為商業(yè)智能(BI)和報(bào)表提供高性能查詢(xún)。現(xiàn)代架構(gòu)常呈現(xiàn)“湖倉(cāng)一體”趨勢(shì),以融合兩者的優(yōu)勢(shì)。
二、 數(shù)據(jù)處理:釋放數(shù)據(jù)價(jià)值的核心引擎
數(shù)據(jù)處理是賦予數(shù)據(jù)生命力的“轉(zhuǎn)化器”,負(fù)責(zé)對(duì)存儲(chǔ)層中的數(shù)據(jù)進(jìn)行計(jì)算、分析和挖掘。根據(jù)時(shí)效性和計(jì)算模式,主要分為批處理、流處理和交互式查詢(xún)。
- 批處理:處理靜態(tài)的、累積成“批”的歷史數(shù)據(jù),追求高吞吐量。Apache Spark 是當(dāng)前主流框架,其內(nèi)存計(jì)算和DAG執(zhí)行引擎大幅提升了批處理性能,取代了早期的MapReduce。它支持SQL、流處理、機(jī)器學(xué)習(xí)等多種工作負(fù)載。
- 流處理:處理連續(xù)不斷產(chǎn)生的實(shí)時(shí)數(shù)據(jù)流,追求低延遲。代表框架有:
- Apache Flink:提供真正的流式處理語(yǔ)義(事件時(shí)間、狀態(tài)管理),并統(tǒng)一批流API,是高性能實(shí)時(shí)計(jì)算的標(biāo)桿。
- Apache Kafka Streams:輕量級(jí)庫(kù),用于在Kafka消息系統(tǒng)內(nèi)部直接構(gòu)建實(shí)時(shí)應(yīng)用。
- Apache Storm / Samza 等也在特定場(chǎng)景下應(yīng)用。
- 交互式查詢(xún)與分析:為用戶(hù)提供亞秒級(jí)到秒級(jí)的快速數(shù)據(jù)探查能力。例如:
- Apache Hive:基于Hadoop的SQL引擎,將SQL轉(zhuǎn)化為MapReduce/Spark/Tez作業(yè)。
- Presto / Trino:分布式SQL查詢(xún)引擎,可跨多種數(shù)據(jù)源(HDFS, S3, RDBMS等)進(jìn)行聯(lián)邦查詢(xún),無(wú)需移動(dòng)數(shù)據(jù),速度極快。
- 機(jī)器學(xué)習(xí)與圖計(jì)算:Spark MLlib、Flink ML 提供了分布式算法庫(kù),TensorFlow、PyTorch 也可與大數(shù)據(jù)平臺(tái)集成進(jìn)行大規(guī)模訓(xùn)練。圖計(jì)算則有 GraphX(基于Spark)等框架支持。
三、 數(shù)據(jù)處理和存儲(chǔ)支持服務(wù):生態(tài)高效運(yùn)轉(zhuǎn)的“潤(rùn)滑劑”與“腳手架”
這一層是確保數(shù)據(jù)存儲(chǔ)與處理流程可靠、高效、安全、可管理的關(guān)鍵支撐體系,常被忽視卻至關(guān)重要。
- 資源管理與調(diào)度:
- Apache YARN:Hadoop 2.0的核心組件,作為集群的“操作系統(tǒng)”,負(fù)責(zé)統(tǒng)一管理計(jì)算資源(CPU、內(nèi)存)并在其上調(diào)度如MapReduce、Spark等計(jì)算框架的任務(wù)。
- Kubernetes:云原生時(shí)代的事實(shí)標(biāo)準(zhǔn),正逐漸成為大數(shù)據(jù)工作負(fù)載(通過(guò)Spark on K8s, Flink on K8s等)的調(diào)度和管理平臺(tái),提供更優(yōu)的隔離性、彈性和混合云部署能力。
- 數(shù)據(jù)集成與傳輸:
- Apache Kafka:分布式流數(shù)據(jù)平臺(tái),充當(dāng)高吞吐、可持久化的實(shí)時(shí)數(shù)據(jù)管道,連接數(shù)據(jù)源與處理應(yīng)用,是流生態(tài)的“中樞神經(jīng)系統(tǒng)”。
- Apache Sqoop:用于在Hadoop和關(guān)系型數(shù)據(jù)庫(kù)間高效傳輸批量數(shù)據(jù)。
- Apache Flume / Logstash:用于日志等流式數(shù)據(jù)的采集、聚合和傳輸。
- 元數(shù)據(jù)與數(shù)據(jù)治理:
- Apache Atlas、Hive Metastore:提供數(shù)據(jù)資產(chǎn)的分類(lèi)、血緣追蹤、審計(jì)和治理功能,確保數(shù)據(jù)的可發(fā)現(xiàn)性、可理解性與合規(guī)性。
- 工作流編排與調(diào)度:
- Apache Airflow、DolphinScheduler:以代碼方式定義、調(diào)度和監(jiān)控復(fù)雜的數(shù)據(jù)處理流水線(DAG),是數(shù)據(jù)工程自動(dòng)化的核心工具。
- 安全與訪問(wèn)控制:
- Kerberos 認(rèn)證、Apache Ranger / Sentry 授權(quán)管理,確保集群訪問(wèn)和數(shù)據(jù)操作的安全性。
###
大數(shù)據(jù)計(jì)算生態(tài)是一個(gè)動(dòng)態(tài)演進(jìn)、分層解耦但又高度協(xié)同的有機(jī)整體。數(shù)據(jù)存儲(chǔ)層如同廣闊的土地與倉(cāng)庫(kù),奠定了容量與持久性的基礎(chǔ);數(shù)據(jù)處理層則是其上繁忙的工廠與實(shí)驗(yàn)室,將原始材料轉(zhuǎn)化為高價(jià)值產(chǎn)品;而各類(lèi)支持服務(wù)則是連接各環(huán)節(jié)的道路網(wǎng)絡(luò)、電力系統(tǒng)、管理章程與安全警衛(wèi),保障整個(gè)生態(tài)的穩(wěn)定、高效與有序運(yùn)行。理解這三者之間的互動(dòng)關(guān)系,是設(shè)計(jì)和構(gòu)建一個(gè)健壯、靈活、可持續(xù)的大數(shù)據(jù)平臺(tái)的關(guān)鍵所在。隨著云原生、人工智能與實(shí)時(shí)化的深入融合,這一生態(tài)將持續(xù)向著更智能、更統(tǒng)一、更易用的方向演進(jìn)。